At Company, we spend 95% of our time thinking about the flow of user data…
…and 5% of the time discussing where to go for lunch. The internet comprises of a complex network of entities, many of them collecting, handling, and processing user data. The data is going on a journey; when a user signs up to a service, or visits a website, that’s just the beginning. What you do with the data after that is just as important.
Stage one: the point of entry
This is where users first visit your site, or sign up to your web app and start using it. It’s the initial point of contact between you and your users — this is the consent stage, where as an organisation, you have to ask you users if it’s okay if you can even collect data at all. This is where all the cookie banners start showing up, unfortunately.
😬The challenges this stage presents: many organisations fall down right at the beginning — they fail to get proper consent from users when it comes to collecting data. How is this?
- Many cookie banners/notices simply do not work: whatever cookies they are asking you to accept haven’t even been blocked.
- A common misunderstanding of what essential cookies are; they are the ones you need to deliver your service to your customers. If you don’t get consent for these, you will be sending data to third-parties without your users even knowing about it.
- There are multiple entry points for user data — not just the first time a user visits your homepage, or signs up to your service. Data enters the cyber-sphere (technical term) in many different places, yet the current standard is to ask for consent on this all at once (inside an ugly, intrusive cookie banner).
🤠Solutions for Entry: at Company, we cannot stress this enough…

Think about it, which scenario plays better in your mind?
- You inform your users that you use Google Analytics to gain understanding of how people generally use your website. You ask if this is okay, and users can choose to say yes or no — an informed decision.
- You inform your users of n o t h i n g and their information gets added to their respective ad profiles, which they know nothing about; the status quo is maintained
There are multiple entry points for user data — not just the first time a user visits your homepage, or signs up to your service.
We realised that entry points are all over the place, and it makes no sense to ask users which entry points they are okay with all at once — otherwise they’re not making clear decisions, and therefore don’t really have control.
The perfect example of this is an embedded Youtube video in a news article : should you expect the readers of that article to decide — before they have even noticed that this article has a video in it — to ‘accept the cookies provided by embedded media’?
Asking a user to predict exactly how they will interact with your site or web app as soon as they arrive is unreasonable, and does not lead to informed consent. That is why Company has built, and will build:
🍪A cookie widget that manages consent for things that may exist passively on a page, such as analytics.
📹Ways to manage the entry of data when it’s actually needed. This means you only ask your users if they are okay with ‘Youtube cookies’ when they press the play button — so they give consent as and when is necessary.
✋Auto-detection of entry points — We are building tools that will automatically detect and block things various entry points that may exist on your site. Deceptively negligible things such as social media sharing buttons will passively collect user data via your site; this actually goes against regulation, which is why we are building tools to manage this.
So controlling your entry points is important — in many cases, you could be a user-data gateway to third-parties. You can’t control what third-parties do with data, but you can control what data you collect.
Stage two: Process
This is the stage where user data has entered your particular data-sphere, and you now have it stored somewhere. Maybe it’s stored locally with you or maybe it’s in some kind of third-party cloud storage. And even then, do they not share the data with others themselves? Where is this data going?
These are exactly the questions that start cropping up if you spend more than half a minute thinking about data processing. We realised that just ‘having’ data is not a thing — it’s more complicated than that.
😬The challenges this stage presents can be perfectly summarised by this diagram:
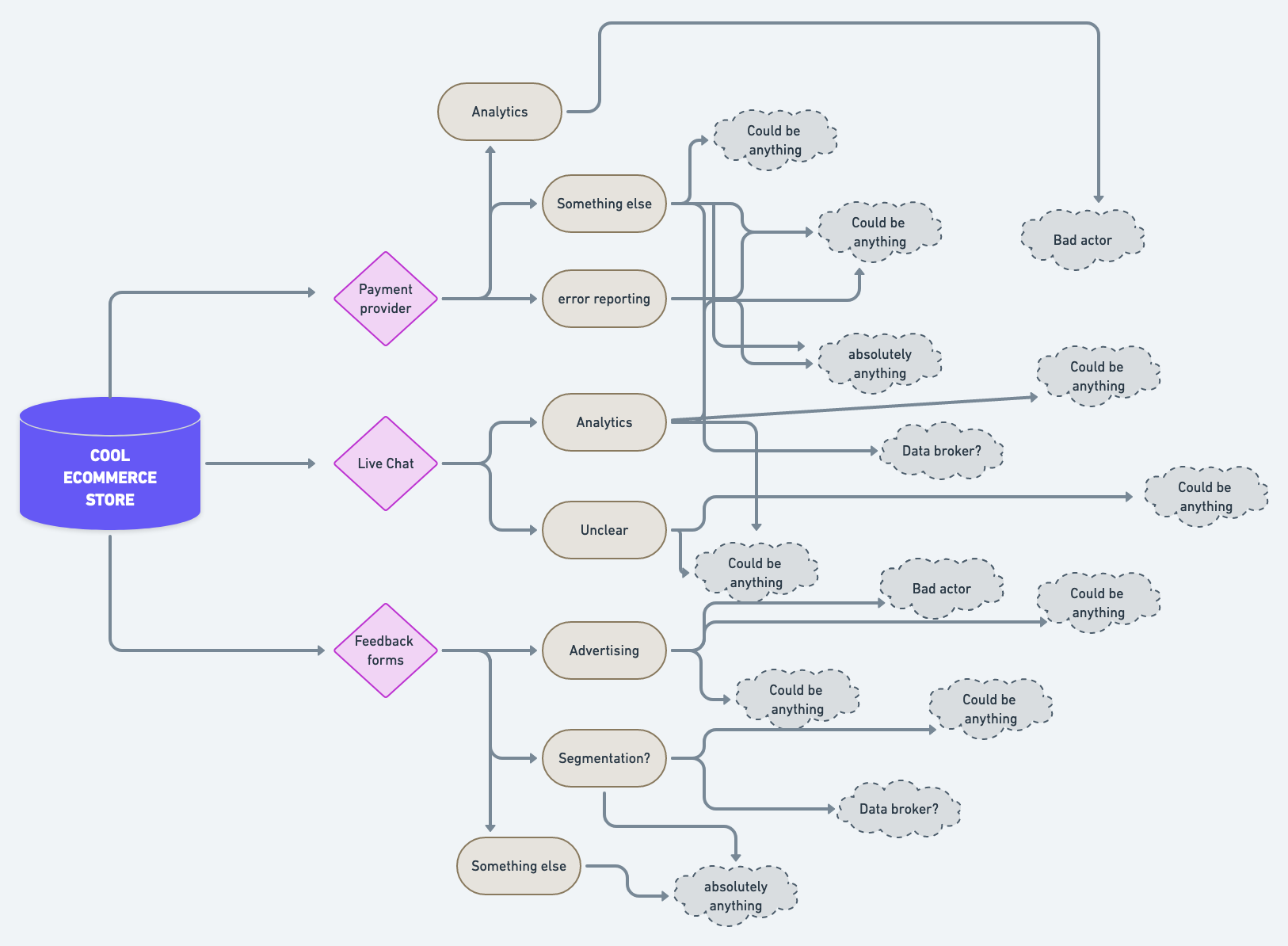
Here’s a hypothetical map of where user data could go if you ran a cool e-commerce store. As you can see, you’ve used three third-parties to help you power your site: a payment provider, a live chat widget, and an embedded feedback form for customer comments.
These things are fair enough, because they are necessary part of getting on wit day-to-day business. But we’ve realised that third-party providers simply represent the multiple entry points for user data — once third-parties collect this data, what do they do with it?
🤠Solutions for Process: are about understanding where else the data goes after your users agree to share it with your third-parties.
Sure, you boast that you don’t share any data with Google via your cool e-commerce store, but the third-party who designed your feedback forms include Google Analytics with their embeds — because they are collecting analytics on their product which is on your site.
🗺 This is why we’re working on a provider map which is built using the same tech that powers TrackerTracker. It will show a tree of providers coming out of your domain, like the diagram I drew above, but actually useful and informative.
Having this information is useful, but even better if you get updated whenever there’s a change: for instance, if you are indeed trying to avoid Google as much as possible, you will get notified if any of your providers start using a Google product.
So in Process, you are keeping an eye on what’s happening with your users data, now that they have trusted you with it.
Stage three: controlling the data.
Your users produce data by engaging with your product; they’ve given it to you through entry points, and trusted you to process it responsibly. But ultimately, they have rights over how to control it.
😬The challenges this stage presents become apparent as soon as one of your users make a subject access request. This is where a user decides to exercise their data rights, which include asking to see, change, restrict, and completely remove any data you may have about them. This means you have to:
- Know where every user’s data is kept, so you can find it easily
- Have a way of easily extracting the data and put it into a meaningful, readable format for your users
- Make sure that you’ve included any additional data that has been gathered by your third-parties.
Taking proper steps during Entry and Process makes Control much easier. You can’t fulfil subject access requests properly if you don’t keep track of how data is entering your organisation, and where it goes afterwards.
🤠Solutions for Control: concern how subject access requests are managed — we’ve seen how crippling it can be to fulfil these requests, to the point where some have built ways to weaponised it.
We see a future where users can indeed click a 'delete my data button' and on your end, that request is completely automated.
If users truly have the right to control their data, then we need to provide tools to enable that control. Sending an unstructured email to privacy@yourorg.com is not sufficient — users deserve their own space where they can easily exercise their rights, like a dashboard or control centre. Imagine if a user could remove their data from your organisation with the click of a button?
Once that button is clicked, there’s no reason why this task can’t be handled like any other one — startups use tools like Trello and Notion to improve workflow all the time. The same attitude can very easily be applied to managing data requests.
At Company we see a (near) future where users can indeed click a ‘delete my data button’ and on your end, that request is completely automated.
In understanding the journey of user data, we can see that managing user data is not a resource-sapping chore, but a necessary part of your operation. In other words, it’s important — but that doesn’t mean it has to be hard. It’s just like paying an invoice or booking a meeting; protocol on how to manage this is clear and straightforward. Managing data should be the same.

Georgia Iacovou
Content Writer