Fun fact about data trusts: they don’t exist yet
Data trusts are just an idea — but they one of the more interesting and challenging ideas about data that we’ve come across so far. The point behind a data trust is to extract value from data without being evil. Sounds hard, haven’t seen that been done yet. The data trust model suggests that there may be a way…
But how does data even have value and how is it we aren’t getting any?
A couple of weeks ago we published this piece which explores the difference between personal data and behavioural data. We produce heaps of this data all day everyday and hardly see it, or even get to interact with it. The cost of using Facebook is producing this data and passively shovelling it into its greedy data hole.
The value you’re getting out of this is something intangible and difficult to measure; what do you even use Facebook for these days? Organising events? Maintaining a professional network? Staying caught up with family? Sharing hilarious memes? Cool okay — all these things are really different but they definitely have some kind of value. BUT it’s absolutely nothing compared to the value that Facebook manage to extract from all our juicy collective data.
Just to put things in perspective, last quarter Facebook announced revenue of around $15 billion. So that’s $40 per user per year. And there are 2.38 users right now. They also said they put aside about $3 billion to pay FTC fines (you know, just because they can afford to). I mean… these are nonsense numbers.
So yes, the value that we as individuals get out of Facebook is the equivalent of a sad little maraschino cherry, while they get to eat a million sundaes. And do you know what’s cooler than a million sundaes? A billion sundaes — to paraphrase an atrocious quote from a terrible movie.

Data isn’t just for adverts; you also use it to make stuff…
Yeah I know I genuinely thought that our data was just used to sell use Rick and Morty T-shirts but okay. Ad networks such as Facebook and Google are so powerful because they are the ones with both the access to our a billion sundaes, and the resources to process those billion sundaes.
Facebook is just an example — there are loads of services and apps that also milk users like data cows and only leave us with enough for one cup of tea a year. Facebook is an interesting example because it has a lot of data, and it’s all very informative; Facebook knows so much about all of us and all they’re doing with it is making stupid adverts researching how they can best market their blasted ‘privacy pivot’. What if the breadth of Facebook’s data was suddenly made available to someone doing psychological research? Just think how much we’d learn about the human race.
But in order to actually understand what a data trust is, let’s look at more practical examples. The idea behind data trusts is making it so that we all get something out of all that data we produce for the system. That means, companies like Facebook don’t get to keep all that valuable data for themselves — others actually get to use it to build meaningful things of their own. Let’s start out with a super basic example:
Imagine you just turned vegan and eating fried tofu and avocado toast every day has given you a very strong desire to see how actual professionals cook vegan food. Guess what: there’s an app for that. It’s basically a map of restaurants that serve vegan food. Simple yet effective.
What sort of data is needed for this app to work?
🍦 Data about restaurants: where are the restaurants, whats the food, etc.
🍦 Your location data so you will be shown restaurants near you
🍦 Map data so you can see the restaurants on a map
🍦 This is just an example so please don’t jump down my throat about what you would actually need to build this app…
As a maker of apps in our current reality, you’d probably get a lot of this info from Google. If data trusts existed, you’d get all this stuff from one of them. Confused yet? Just look at this cool diagram I drew:
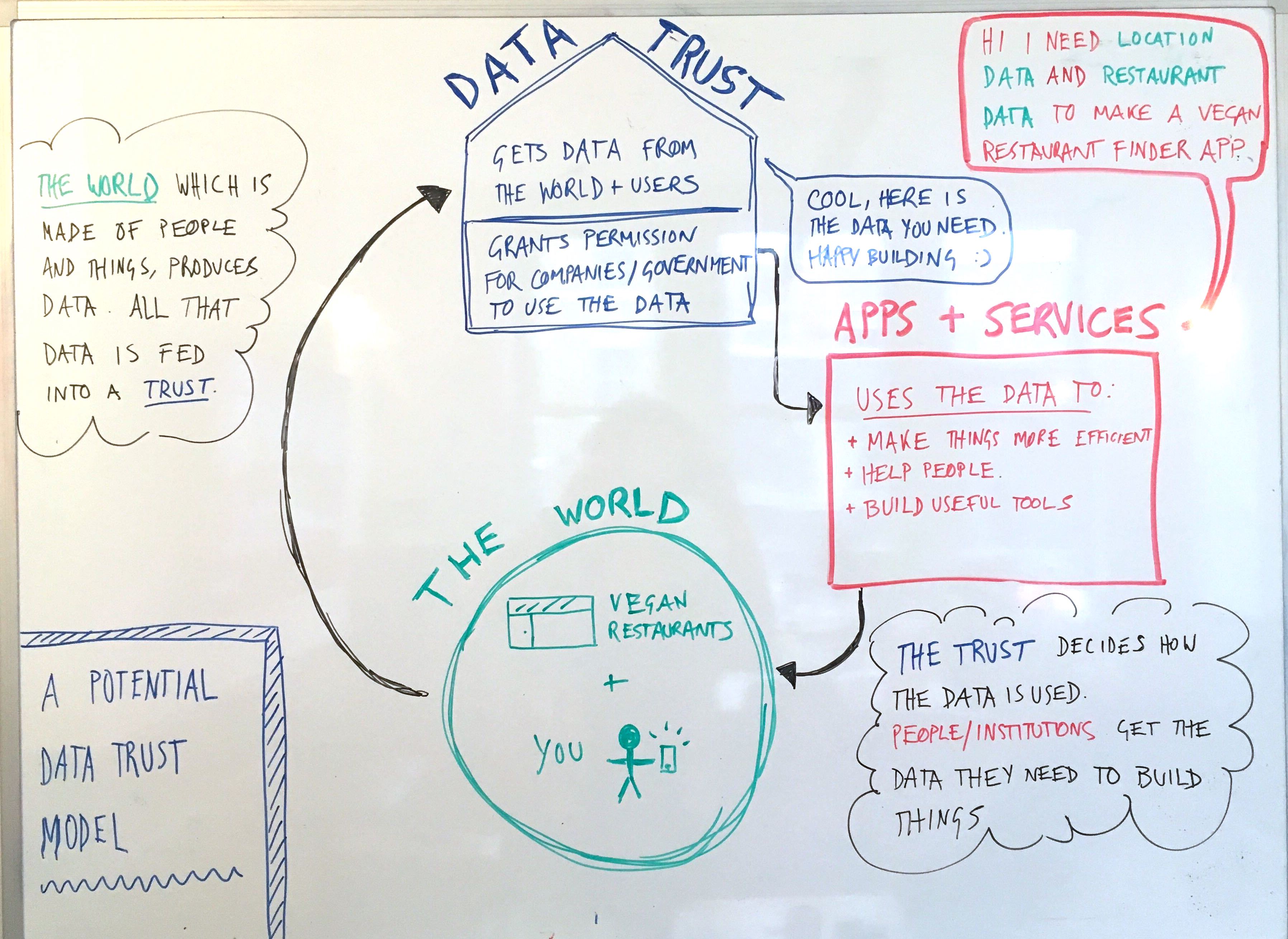
So the data trust decides what data is used, and how it’s used. But whose interests does the data trust protect? Ideally, everyone within the cycle in my diagram above, which is:
- The people producing the data: ensuring their data is not mishandled, and protecting people’s privacy
- The people using the data: ensuring that people make good apps and design high quality services that actually harness the power of the data available to them.
- The trust itself: the people who work for the trust and are looking after the data have to be the right people otherwise the trust won’t work.
So in other words, if the world was suddenly flipped on it’s head and there were data trusts all over the place, Facebook would then have to ask, “hey uh can I have all that data I had before so I can spunk out heaps of adverts all day every day?” And then a data trust would probably just say… no. That is because handing that kind of data over for that purpose really has nothing to do with protecting the interests I outlined above.
Okay but answer me this: How does the data trust even get hold of the data in the first place?
Yes, good question. If we are using all these apps and services to produce the data, how is the data trust the first entity to get their hands on it? Instead of just guessing the answer to this question, I went ahead and asked a data governance expert called Anouk Ruhaak, and she said this:
So, the trust sort of becomes the data storage for the platform. Much in the same way the new ‘decentralised web’ gives control of data to the user, rather than the platform (e.g. Holochain or Solid). That probably implies the data should be structured in a specific way, so the trust automatically knows how to store it. Anouk Ruhaak, Data Governance Expert
Currently, when you post something on Facebook, that gets stored in one of Facebook’s data centres (somewhere cold like Sweden). What Anouk is saying is that under a data trust model, when you post something on Facebook, it zips straight over to the data trust and Facebook actually have to ask for it back. Please look at this other nifty diagram that I crafted to illustrate what I mean (why conceptualise when you can visualise, amirite?)

As Anouk mentioned, this also means that the data needs to be structured in a specific way; for example, some kind of universal format. This is so that data portability can be achieved. And what that means is, when/if someone who isn’t Facebook asks for this Facebook-related data, they will be able to read and process it. In other words: it has potential to be useful for everyone, not just Facebook (or whatever platform was used to produce the data).
What I’ve outlined so far about data trusts could make the following things possible:
- Apps that are very similar to Facebook can finally exist and you could actually QUIT FACEBOOK FOR REAL (hallelujah) because there will be viable alternatives for you to choose from.
- The data you produce by using any app or service could be seamlessly transferred to any other app or service; just look at what happened to April in Rightworld when data generated by her health app massively improved the service at her GP.
- Any data you produce purely by existing could be used for so much, including improving city infrastructure and tackling big problems such as food waste.
So you see, data trusts could allow new businesses to thrive (because data portability aids innovation) AND increase social mobility and the quality of public services (for the exact same reasons as why it would be good for business). Wow, okay… who knew you could improve both of those things at the same time? Yep, cool.
Data trusts seem hard. Are they, or am I being silly?
Oh no friend, they are very hard indeed. There is a lot to consider when it comes to data trusts. First of all you have to actually — pun overwhelmingly intended — trust the trust. You have to know that the trustees will actually have the interests of those producing the data and those using the data at heart. Anouk says that one way of achieving this is ensuring that a data trust is not-for-profit, because:
History witnessed many examples of corporations prioritising profit (and arguably survival) over the protection of their customers, even when doing so was unlawful […] We hold that valuable datasets should never be held by for-profits in the first place as the weaponisation of such data is inevitable, and the temptation for abuse is simply too high. Anouk Ruhaak, Data Governance Expert
Dunno about you, but I definitely feel like we’ve tried the for-profit way of doing this, and it hasn’t really worked. Unless you consider Cambridge Analytica ‘working’. For Anouk, the most important element of a data trust is that it acts as a “custodian with a fiduciary responsibility to safeguard the privacy of the people the data is about”. So if an institution is not distracted by the idea of making profit, they may actually be more compelled to protect the privacy of the general public, while still extracting value from the data.
Some institutions such as the Open Data Institute have tested out how a data trust might actually work. They’ve implemented a few pilot programmes including this one to tackle illegal wildlife trade by using data captured in the wild (images and audio of animals) to alert the relevant authorities in real-time of any illegal activity. Others who’ve tried using a data trust model to get things done include WRAP, who want to tackle food waste and Sidewalk Labs, who want to turn Toronto into a smart city.
Another data trust hurdle is the handling of sensitive data. When talking about the Open Data Institute’s illegal wildlife trade programme, Anouk mentioned that microphones set up in the wild could also, inadvertently, record conversations that happen between humans. That data could be sensitive, and has nothing to do with what the microphones are there to achieve. But it is, nonetheless, data that exists and has to be dealt with.
Ultimately, a successful data trust needs to find a balance between protecting the people who provide the data (you, me, and everyone in between) while still facilitating innovation for those who want to use the data (apps, services and, yes, even the government).
Right now, the thing with data trusts is that setting one up is a very large challenge, and no one can really know if they would even work. No one is saying that data trusts are the answer, but they are one radically new idea in a deep, cold sea of a billion sundaes 🤷🏻♀️ 🍦
Anouk Ruhaak is a journalist and engineer who has written extensively about data governance. She worked as lead consultant for the Open Data Institute. Go here to read about her current workings with data trusts and also follow her on twitter if you want.

Georgia Iacovou
Content Writer